I rewrote the Scratch image server in Go
Scratch started in August 2025 as a simple Node.js server, local file system, and a hard coded whitelist of allowed user agents. That was it. A single process answering HTTP requests off a directory of files. It was small, simple and quick.
When Scratch started to grow, I started making changes to scale it. This is about one of those changes.
Back when Scratch had ~1,000 images stored and only serving 10-100 images a day, having NodeJS just handle the image serving made sense, it was quick, already tied into everything else and pretty easy to get going.
Fast forward to now, serving 30-50K+ images a day and hosting about 72K images. What worked back then just doesn't work now. The cracks starting to show Nodes started crashing. Cascading outages started happening, at the time, my solution was just throw more servers at the problem while i looked for something better.
So I started researching. In February/March I was comparing Go, Rust, C++, and even Zig for this specific job, to run the image server.
Go won. Not because it's the fastest. It probably isn't, against tuned Rust or C++. It won because it did what I needed without stupid complexity and its a pretty simple language to jump into.
The plan was a sidecar: Go handles the simple 85-95% of the daily traffic, Node does everything that has complex logic in it (for now). I didn't want a full rewrite (yet). A full rewrite means I'm not making any changes until it's done.
A sidecar lets me move the hot path off Node while keeping every other endpoint exactly where it is. If the Go server has a bug, it can route around it. If it's better than I hoped, I can move more to it later.
This setup started handling production traffic on June 14th, 2026.
How it works
Requests still come in normally. The http server looks at the request and decides where to send it. If it's a plain image GET from a client, the new image server grabs it (so about 85-95% of the time). Everything else stays in Node (5-15% of the daily traffic).
The Go server has three layers, set up just like its JavaScript counterpart: an in memory cache, a disk cache, and S3 as cold storage. Memory holds the hot working set. Disk holds everything that's been requested recently enough to be worth keeping local. S3 is the source of truth.
The big change is how it handles a cache miss. The old NodeJS version did the obvious thing: check memory first, then disk, then fall through to S3 if both miss. That's correct, but it stacks the latency and that stacks up quickly and very rapidly.
The New Go version kicks off the S3 fetch immediately and then checks disk and memory in parallel. If a local cache has the file, it cancels the S3 request before any bytes come back and serves from local cache. If disk misses, the S3 fetch is already in flight and the image is on the way with out having to wait.
This is the kind of thing that's easy to write in Go and a pain to write correctly in Node, and why I picked it.
The numbers
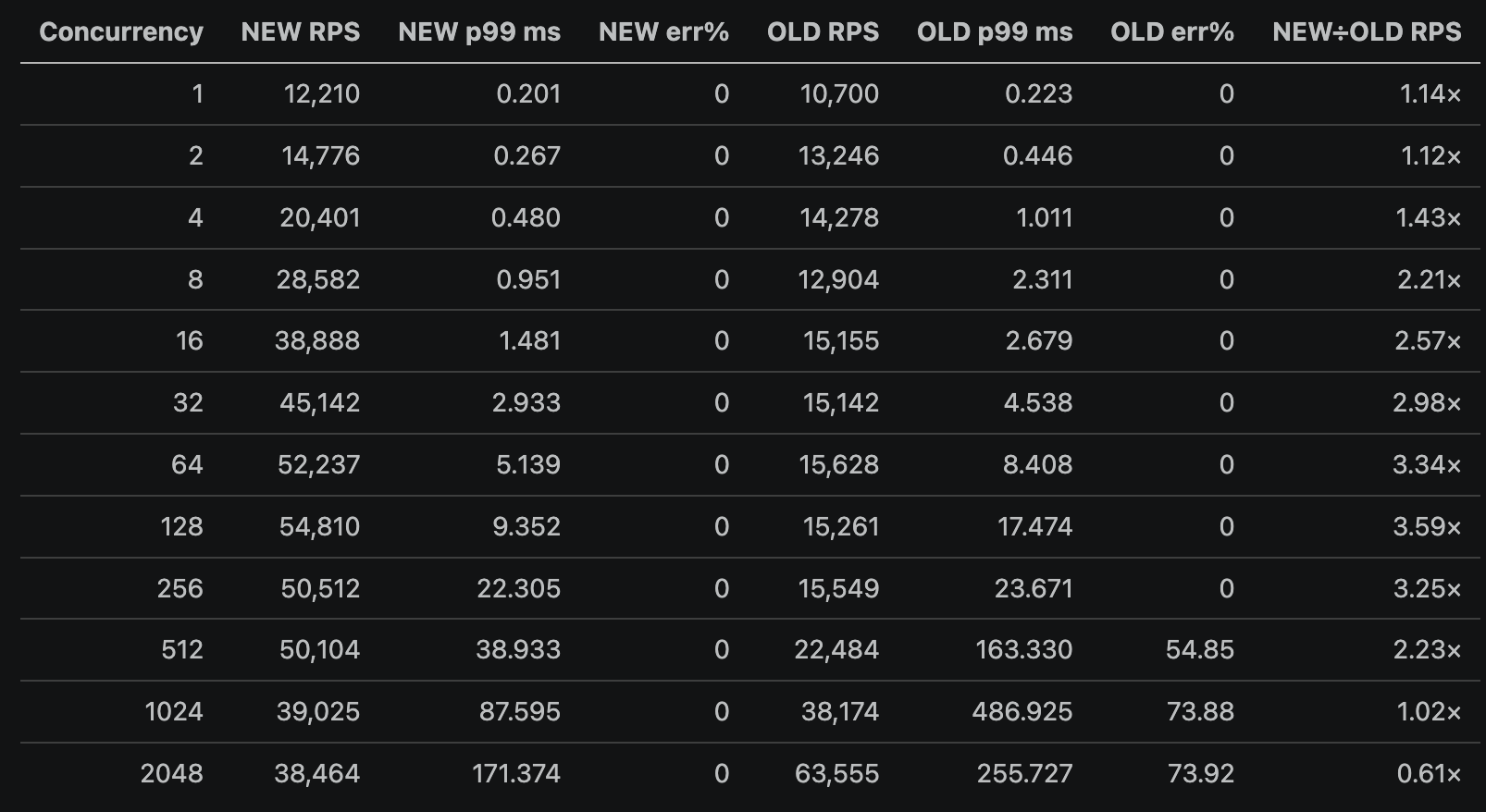
(RPS = Requests per Second)
I ran the load generator against both servers under identical conditions: same disk cache directory, same test database, same S3 buckets, same network and same computer. Only the binary changed between runs.
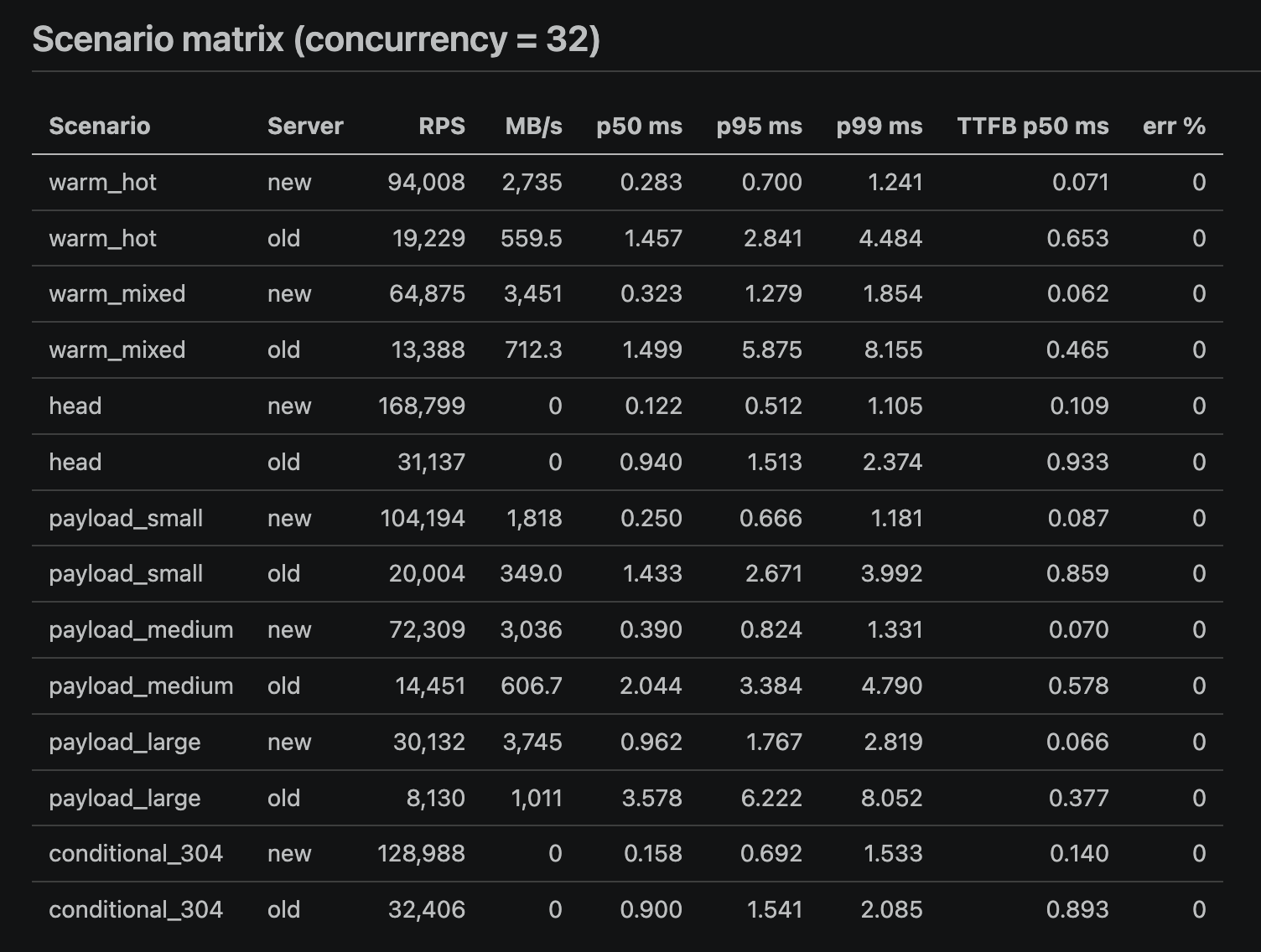
Warm path at concurrency 32:
| Node | Go | |
|---|---|---|
| RPS | 19,229 | 94,008 |
| p50 latency | 1.457 ms | 0.283 ms |
| p99 latency | 4.484 ms | 1.241 ms |
| TTFB p50 | 0.653 ms | 0.071 ms |
About 5x the throughput, 5x faster median, and 9x faster time to first byte. The TTFB number is the one I actually care about. Bytes can stream after the first byte. The first byte is the wait.
The stress ladder is where it gets interesting and the biggest difference is noticeable. Node plateaus around 15-19k RPS no matter how much concurrency you throw at it. At c=512 it cracks and starts dropping 54% of requests. At c=1024 it's 73% errors. Go scales the other way: 12k RPS at c=1, 54k at c=128, and then stays clean all the way through c=2048 with zero errors. Peak CPU for Go was 304%, so it's actually spreading across roughly three cores. Node never got above 157%, which is one core plus a little thread pool that isn't doing anything useful for this task.
This is the part that actually matters in production. Average throughput is a nice number. What you really want to know is what happens when something upstream misbehaves and you get a burst.
Memory at peak load during the stress run: Go 111MB, Node 385MB. About a third of the footprint.
(both of these images are hosted on Scratch :P)
What's next
With the sidecar handling its part of traffic. The next thing on the list is moving a couple more endpoints over, starting with the ones that are mostly I/O and don't need to touch the more complex parts of the Node codebase. Anything that's "look this up, return it" is a candidate. Anything that touches the upload pipeline or the auth layer stays in Node for now, because that code is well tested and not the bottleneck.
Node was right for August 2025. Go is right for June 2026. Its crazy how much can change in a year :)
(stats as of posting): Images: 72025 Users: 1988 Req/day: 30569.7